文章简介: 本文是我在《F5 NGINX Sprint 2022》大会分享的文字版整理。《NGINX网络协议栈优化》有两个关键词,第一个是网络协议,因此不涉及 NGINX 的业务模块。第二个关键词是性能优化,目标是让NGINX的性能达到目前硬件架构的极限。
很高兴大家回到这次深潜之旅,让我们继续挖掘 NGINX 的潜力。今天我的分享包括四个部分。首先从整体上来看一下 NGINX的协议栈如何进行优化。接着我们将按照 OSI七层网络模型,自上而下依次讨论HTTP协议栈、TLS/SSL协议栈以及TCP/IP协议栈。
首先要明确NGINX的优化方向。优化的目标在我看来可以用三个词表示——快、多、省。
- “快”是指降低请求的时延,请求时延是用户能够感知到的最明显因素。
- “多”指的是 NGINX正在处理的所有TCP连接数量以及收发的总字节数,比如总吞吐量能否打满网卡。
- “省”指处理一个 TCP 连接时所消耗的资源要尽量的少,这样我们的并发连接才能够达到千万、亿级别。
在做协议栈优化时,我们必须同时兼顾知识深度和广度。开发习惯从实现的角度看问题,知识面倾向深度。而运维更关注服务部署、运行,比如要了解IDC地理位置、网络规划、服务器硬件配置等情况,因此知识面是倾向广度的。NGINX运行在 Linux 或者 FreeBSD 等操作系统上,操作系统的内核协议栈和进程调度机制都会影响 NGINX 性能,所以优化内核参数时相对更需要深度。了解 NGINX 所在网络环境,针对丢包率、网卡特性、CPU特性、交换机和防火墙的规格、协议特性等要素优化 NGINX 时,相对又会偏重广度。
NGINX 协议栈优化方法论
首先我们看下面两张图,先同步下思路。
NGINX架构
第一张图由 NGINX 官方提供,我们从三个层面来解读它。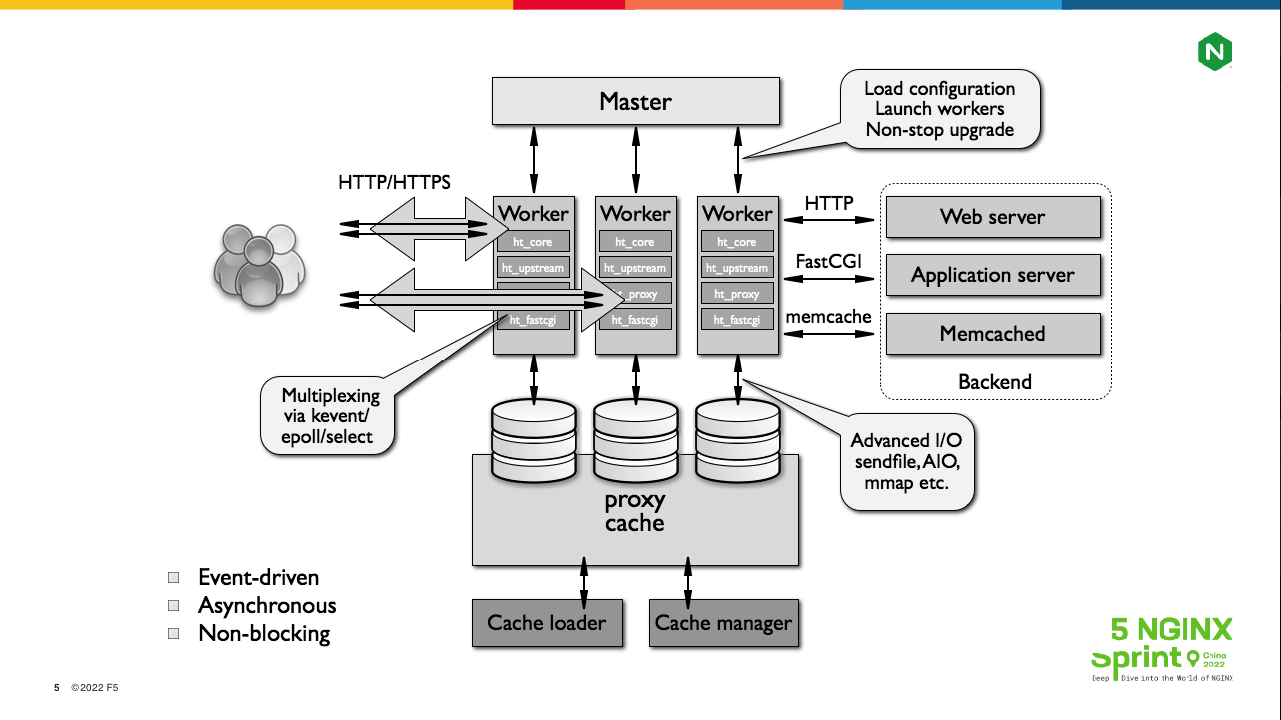
第1个层面是左下角的 3 个关键词。
事件驱动Event-driven: 什么是事件呢?比如接收到TCP握手的SYN或者FIN报文,或者接收到ACK(发送缓冲区被释放出来),或者某个定时器执行结束,这些都是事件,而NGINX对请求的处理是由这些事件触发的。
非阻塞Non- blocking: 指当你将socket设为非阻塞模式后,操作系统提供的POSIX API就能在未完成任务的情况下返回,比如建立连接的connect系统调用可以在未完成三次握手时就返回成功。
异步Asynchronous: 面向开发人员的一种编程模式,它需要为每个请求维护上下文,并频繁更换状态机,非常复杂。当然,如果你使用了Lua协程,这种同步模式会降低复杂度,但在NGINX的C框架层仍然是异步的。
通过这三个关键词可以看到,NGINX 即使不做优化,性能也还不错。
第2个层面,再来从左至右看图中的网络流向。左边是下游客户端与 NGINX 之间的流量,主要是指HTTP协议。右边是 NGINX 与 IDC 内的各 Web server 传输的流量,它的交互协议种类比较丰富,但都能与HTTP协议进行语义转换。比如,当上游服务是Memcached 或者Redis时,存取缓存元素可以对应HTTP中的GET或者PUT方法(参见Roy Fielding的RestFul架构风格)。
第3个层面看进程架构。NGINX 有一个 master 父进程、多个 worker 子进程以及可选的cache manage和cache loader子进程。当然,如果你使用了NGINX的二次开发生态,还会多出一些进程,比如OpenResty可能产生的privileged agent子进程。master进程不处理网络流量,实际工作的是 worker 子进程,其他子进程都是用于配合worker进程处理请求的。比如HTTP缓存会存放在本地磁盘中,cache manage负责缓存的定时淘汰工作,而cache loader则在NGINX重启时载入磁盘文件。
NGINX也可以作为Web server使用,本次分享不涉及这块。今天主要讨论NGINX作为负载均衡的优化方法,除网络协议外,还会涉及一些磁盘 IO 知识。
再来看第二张图,它是OSI网络七层模型与真实的TCP/IP协议间的对应关系。模型是为了方便我们理解概念,而解决问题必须分析真实的协议。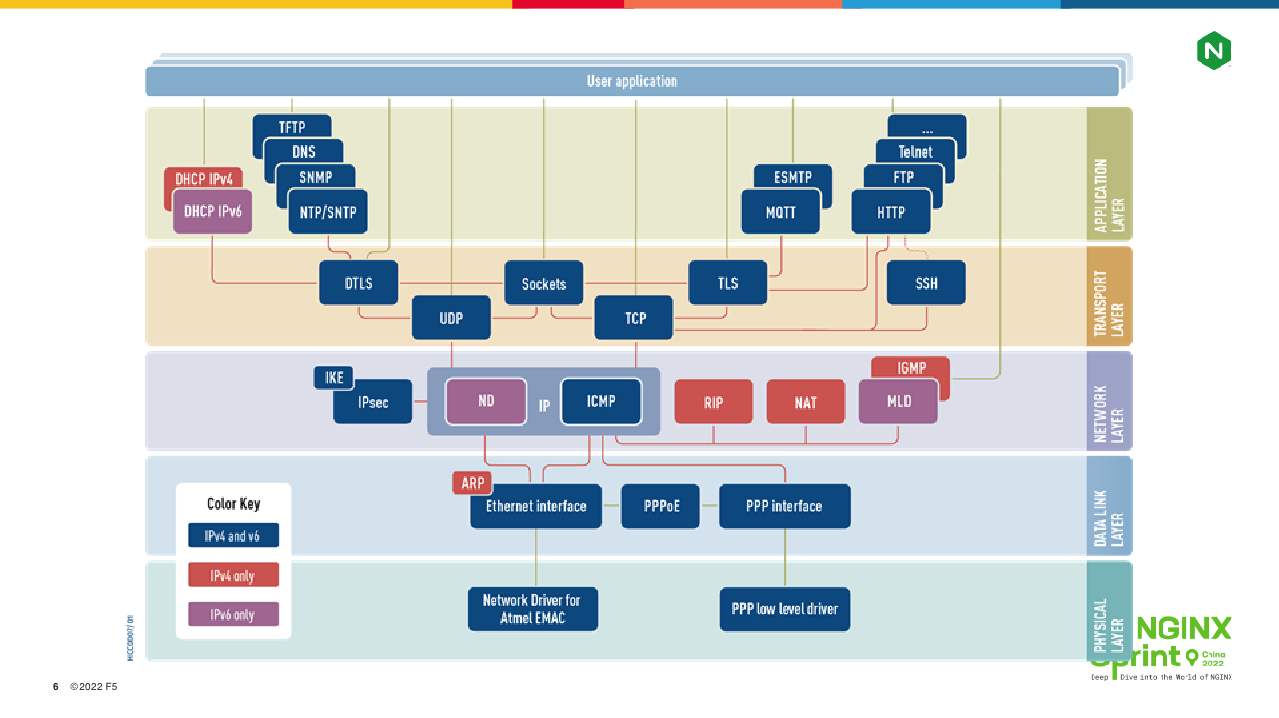
比如,应用层中我们最常使用的是HTTP协议,它是由NGINX框架代码执行编解码的。表示层中常用的是TLS/SSL协议,它由NGINX进程中的openssl库执行编解码。传输层常用的是TCP协议,网络层是IP协议。网络层与链路层之间的定义则没有那么清晰,比如VLAN(802.1q)、ARP协议等可以近似归到这两层。以上传输层、网络层、链路层中的协议默认是由操作系统内核处理的,它们通过socket及一些系统工具(如ifconfig、route)提供给NGINX使用。
协议栈优化场景
接下来我们用4张图,看看协议栈优化的具体场景。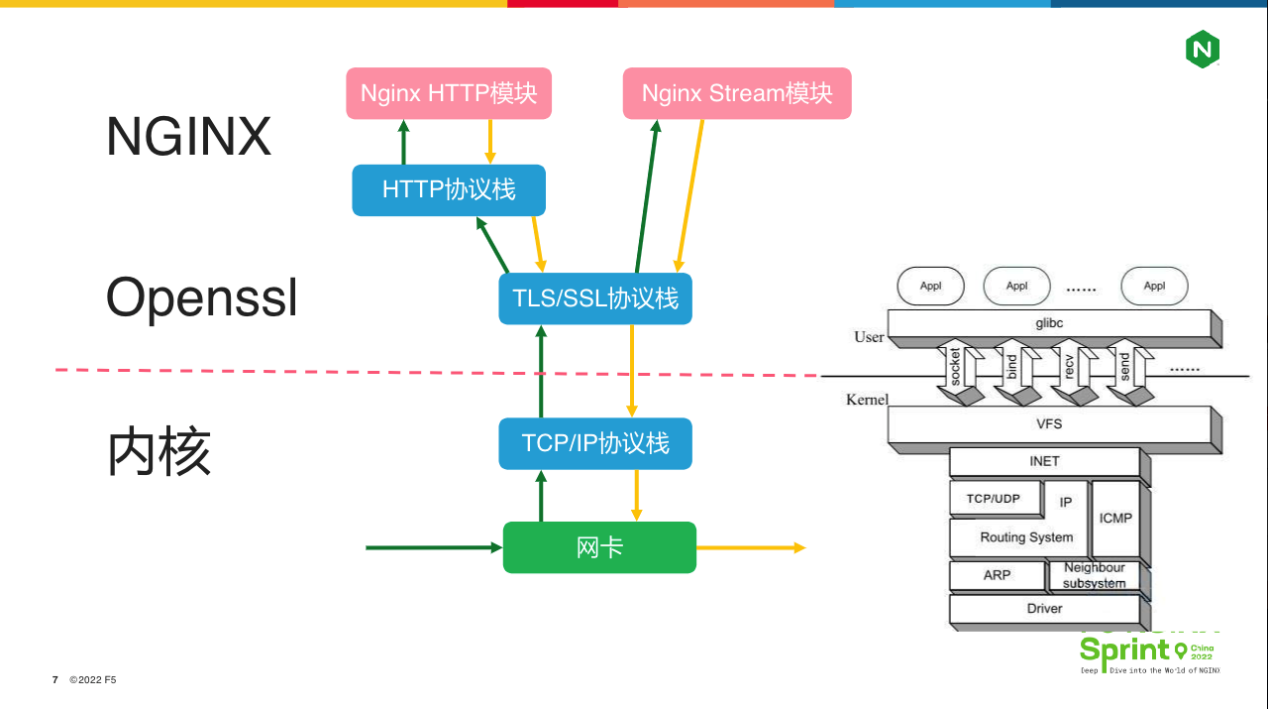
第一张图最常见。当网络报文到达服务器时,首先会从网卡来到内核的 TCP / IP 协议栈,处理完毕后经由右边的 socket 及 listen()、 bind()、recv()、send()等系统调用进入 NGINX worker 进程,再由 NGINX 框架调用 openssl库卸载TLS 协议,然后基于 http 状态机解析协议。获取到http 请求行、请求头后,NGINX框架就会依次调用各个NGINX http模块处理请求,包括过滤模块和处理模块,以及OpenResty用户常用的 Lua模块。
基于stream模块还可以将NGINX当作 4 层负载均衡使用,当然,这里的“4层”虽然指的就是OSI体系中的传输层,但与传统的4层负载均衡并不是一回事。例如,LVS作为4层负载均衡会部分参与到TCP协议的编解码(仅包含相对简单的握手阶段,不涉及复杂的滑动窗口与拥塞控制),即它会接管内核的TCP协议,而NGINX只是通过socket使用内核处理过的TCP协议。
第二张图可以看到TLS/SSL协议栈同时运行在用户态与内核态代码中,这是怎么回事呢?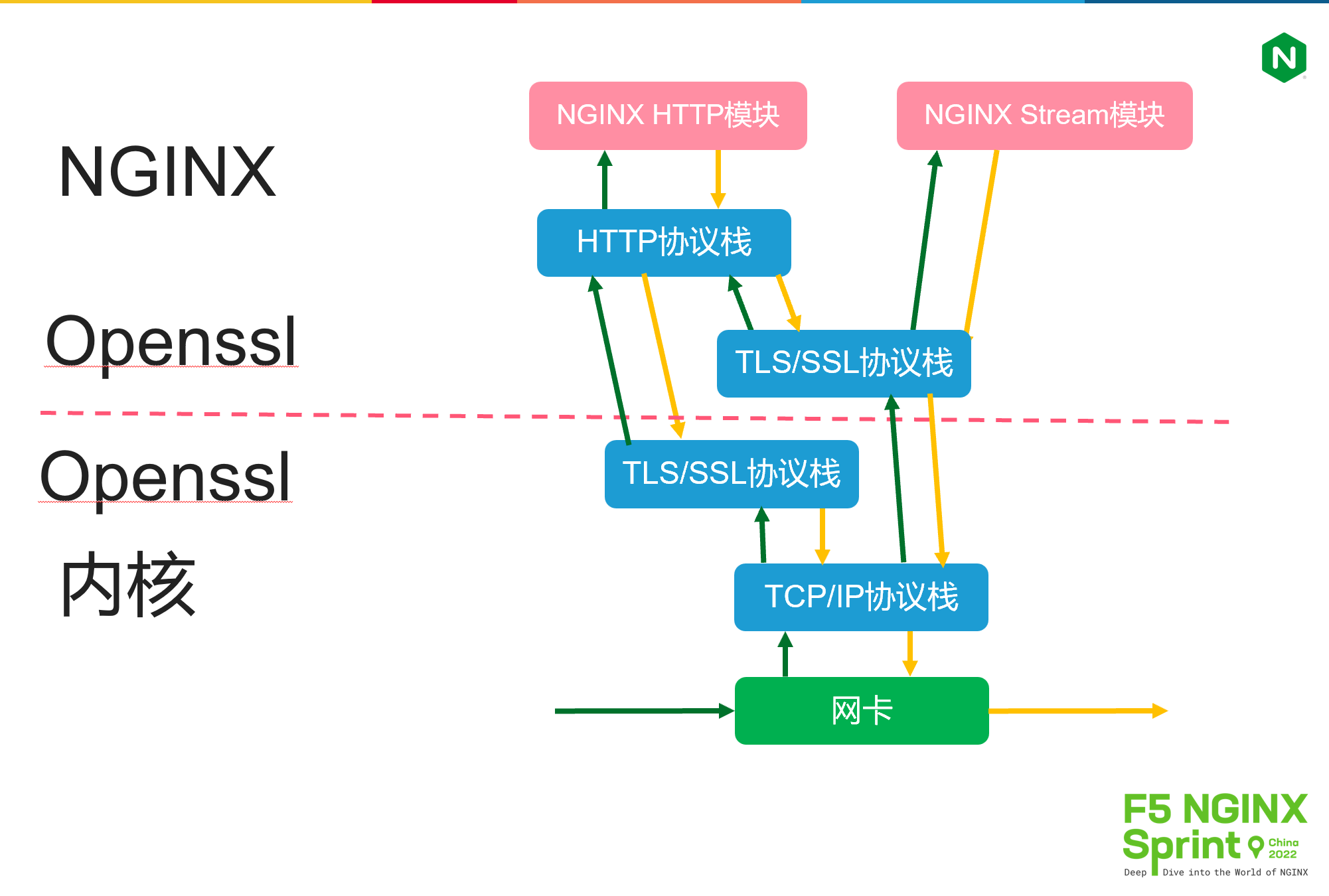
TLS/SSL协议通常运行在用户态进程更合适,这是因为:首先它处于TCP与应用层协议之间,其次它又是消耗CPU的计算密集型协议,所以放在用户态进程中,既能提升应用开发效率,也不会影响性能。然而,在非常规场景下,TLS/SSL运行在内核中性能更高。比如,当NGINX作为CDN缓存服务运行时,缓存文件是放在磁盘中的,一旦HTTP请求命中缓存,接下来将磁盘文件发送到网卡这件工作,就可以通过sendfile零拷贝在内核中完成任务。可是一旦开启了HTTPS服务(当下全站加密是主流),零拷贝功能就无法使用,因为openssl是运行在NGINX进程中的。此时上图中的kTLS方案就有了用武之地。
再来看第三张图。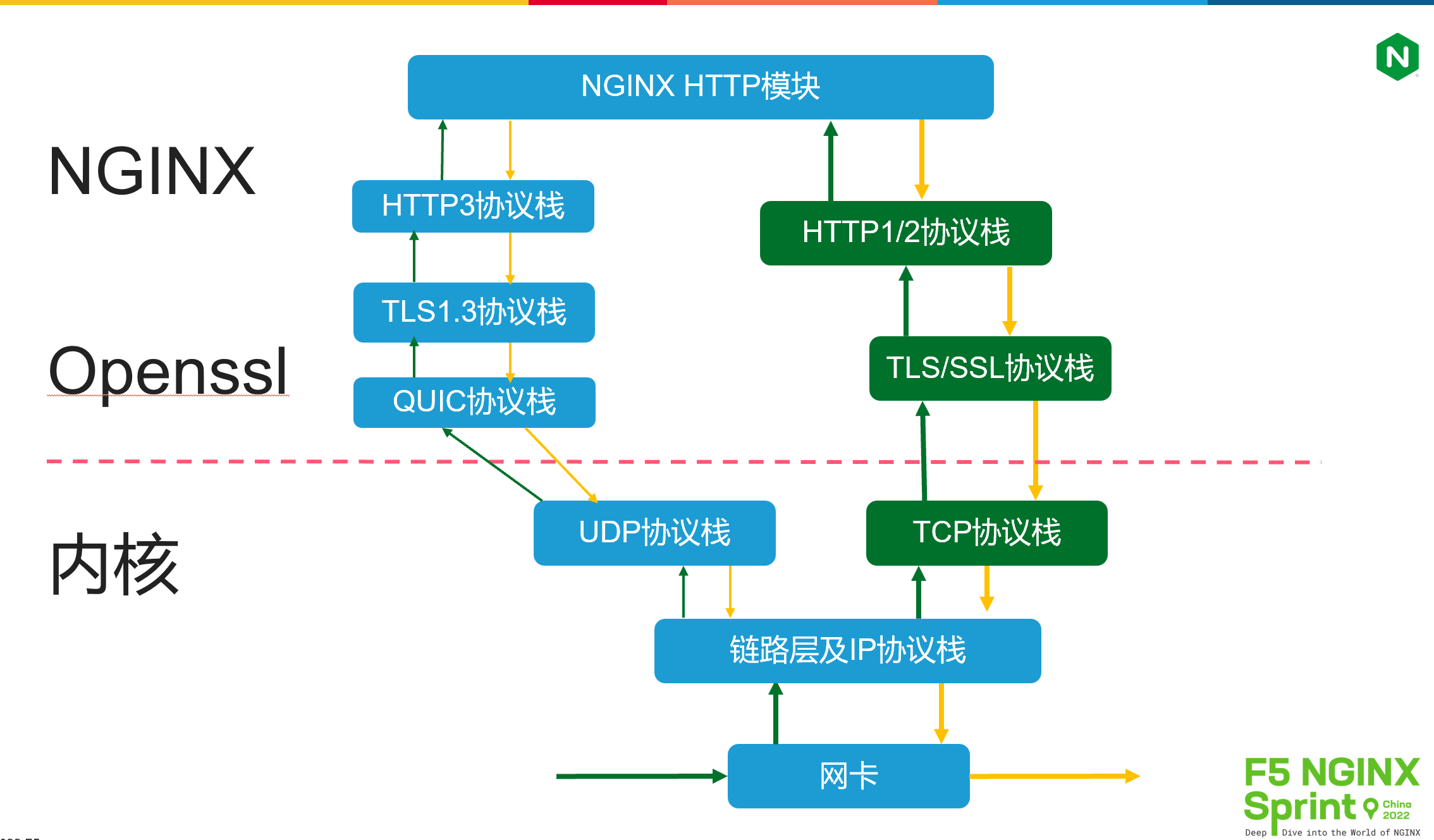
2022年 6 月份,HTTP3协议的正式RFC文档就已经发布,这给协议栈的优化又带来了变数。HTTP3为了解决HTTP2的队头阻塞、连接迁移问题,改用内核中的UDP协议解决进程调度,而将TCP协议中的可靠传输功能放在了用户态的quic协议栈中。因此,我们不再需要通过有限的sysctl指令优化复杂的TCP协议栈参数。
Go、Rust等语言都实现了 HTTP3协议库,但 NGINX 正式版却迟迟没有提供,仅有一个无法在生产环境中使用的quic分支。这里的原因很多,除了开源NGINX非常强调稳定性外,还因为NGINX的多进程架构,它使得连接迁移必须通过eBPF模块,才能在worker子进程间正确地分发报文,这就与操作系统内核紧密耦合起来,进一步延迟了正式版的发布。
另外,常见的TLS/SSL协议都是运行在TCP之上,而现在quic既需要使用TLS/SSL协议,又是跑在UDP协议上,这就改变了TLS/SSL的工作方式。比如,TLS不能对UDP payload整体加密,否则正、反向代理就无法通过connection-ID正确地执行会话保持或者负载均衡(quic不再基于四元组定义连接,而是通过1个64比特的connection-ID定义连接)。
最后来看第四张图,我们深入内核与硬件看协议栈如何优化。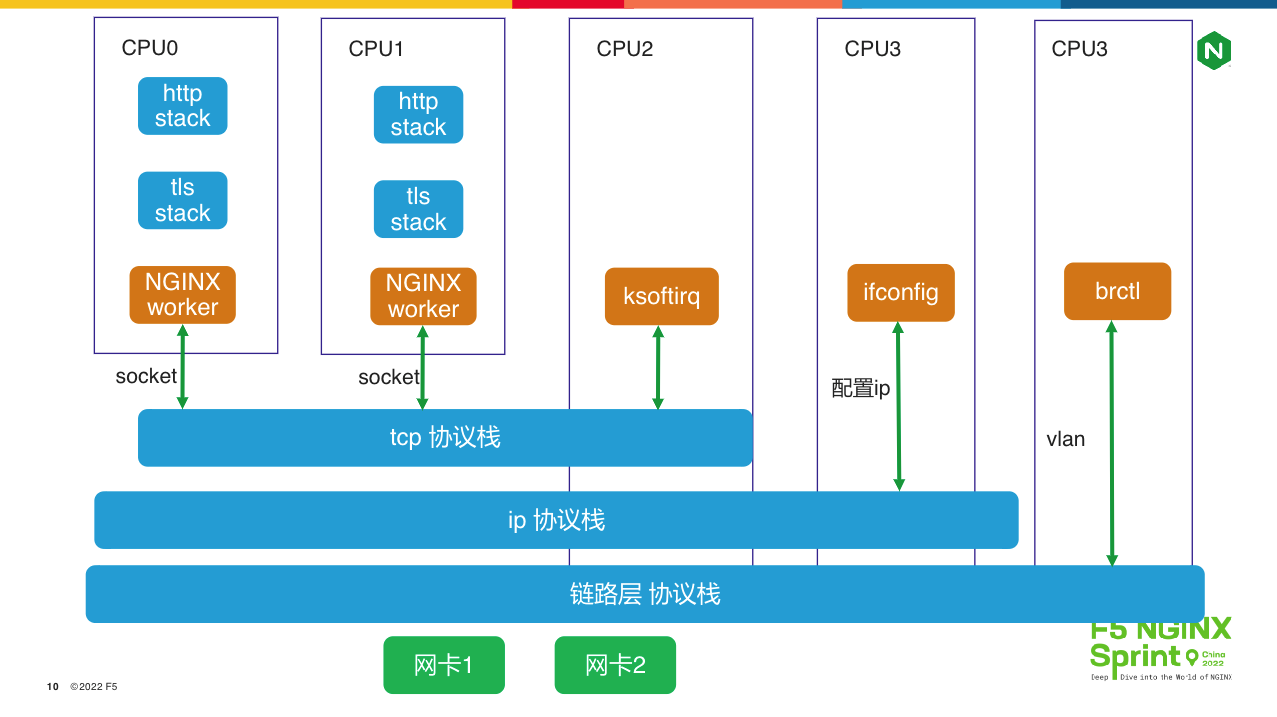
对NGINX熟悉的同学都了解,使用worker_cpu_affinity 指令将worker 进程与CPU绑定时性能最高,因为这样就可以提升CPU的一、二级缓存命中率。但如果我们换个角度想,这意味着每个 worker 进程都有自己独立的HTTP协议栈!然而,这些 worker 进程却共享了操作系统的TCP协议栈,因此listen reuseport指令才有负载均衡的效果。共享提升了开发效率,但却因为加解锁操作降低了运行效率,因此在高并发、高吞吐时,你会发现ksoftirq进程占用的 CPU 很高。
对于更底层的IP 协议栈,它的共享影响范围就更大了,比如listen指令如果没有显示指定IP地址,那么你用 ifconfig 新增地址后,NGINX 就能马上处理新地址上的请求,可以想见这种灵活性的代价:对于满载、多IP的服务器,这种玩法一定会降低性能。IP层之下的数据链路层也有这个问题,通过brctl新增的网桥(做云原生的同学应该很熟悉)和802.1q 协议中的vlan也是可以立刻使用的。
有了总体视角,我们来看应用层的 HTTP 协议栈优化。
HTTP协议栈优化
从互联网的整体发展,我们先来看看HTTP/1.1协议栈的优化点,再来看HTTP2和HTTP3解决了哪些问题。下面这张图是从上世纪80年代起,以太网网卡带宽的演进速度。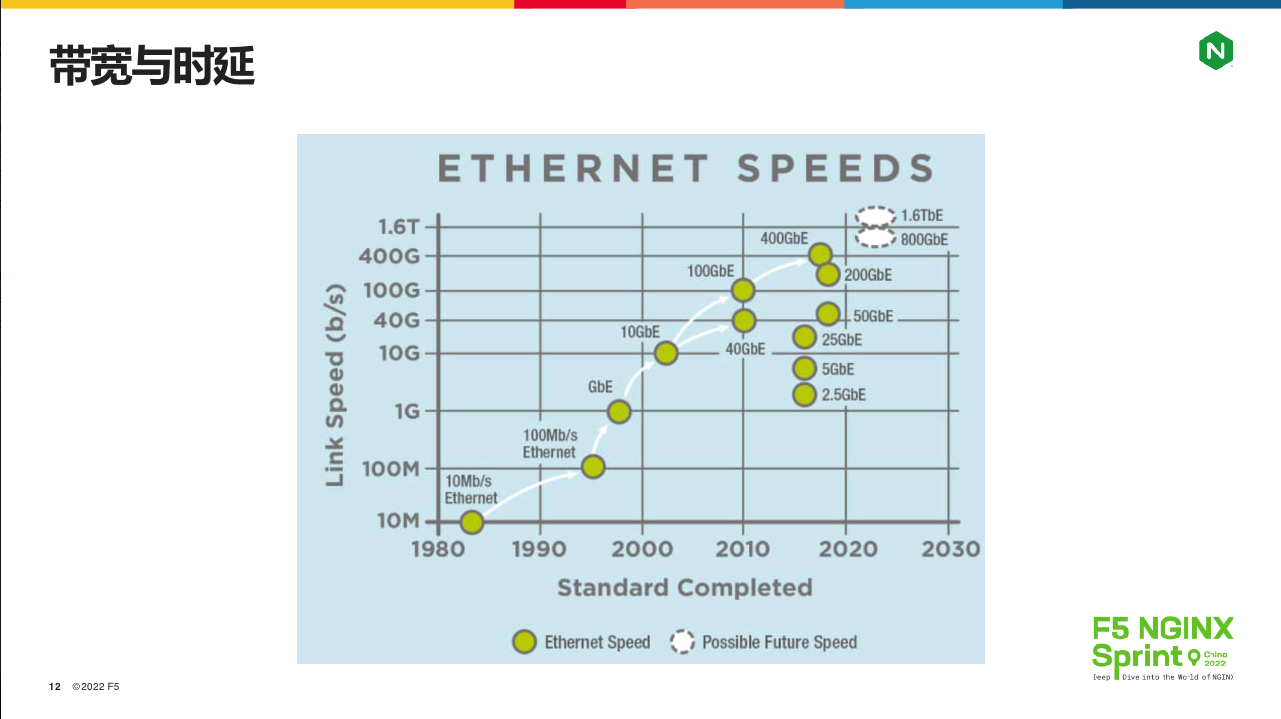
可以看到,在 TCP 协议刚出现的80年代初,网卡带宽只有10Mb/s。到了HTTP/1.0协议出现、互联网开始飞速发展的95年,带宽已经达到100Mb/s,之后网卡进步明显加速,2004年出现了万兆网卡,2010 年 100G网卡,2018年时400G 网卡都出现了。当然,这些百G网卡目前都只在IDC数据中心出现,但这给协议开发人员的信号非常明显:如何才能用满越来越大的单机带宽呢?
与此同时,受制于物理规律(光速),报文在光纤中的传输速度并没有多大变化。必要的交换机中转所带来的“最后一公里”问题,是另一个让网络延迟居高不下的因素。因此,时延几乎不变,带宽却不断增大,协议设计者们有事可做了!
举个例子,十多年前我在设计服务器之间的传输协议时,还会使用gzip之类的压缩技术,因为那时带宽比CPU紧张。而现在IDC内部的带宽提升这么多后,就不再需要浪费CPU在两台服务器上压缩、解压缩数据了,而且消息传递速度还更快。
再比如,早期互联网大厂IDC内的资源利用率很低,因为在线业务的高峰与低谷流量差距太大,为了应对早晚、节假大促日、热点流量的变化,IDC必须预留大量空闲资源。这在早期的蓝海市场没有多大问题,但随着大数据时代的到来,在线业务的数据量以及引发的离线计算量增加的幅度越来越快,必须想办法提升IDC资源利用率。而在百G单机带宽的情况下,存储计算分离这种架构就有了用武之地,通过在线业务与离线计算服务的混合部署,谷歌IDC的 CPU 平均利用率达到惊人的 60% (参见论文Borg: the next generation,与此同时,国内许多IDC只有10%的平均使用率)。
理解了这两个例子,我们就能清晰的看到HTTP协议栈的优化方向:增带宽、降时延。
HTTP1的降时延
先从HTTP1的降时延谈起。单个页面上的资源数以百计,如果下载每个资源都使用独立的TCP连接,就有2个增大时延的因素:TCP握手与TCP慢启动。简单解释下。
一次HTTP资源下载包括2条HTTP消息:请求与响应,客户端在等待响应的过程中,承载HTTP会话的TCP连接只能处于空闲状态,这是HTTP的简单性设计理念决定的。所以,单一页面上百个资源下载任务,只能在并发范围内依次执行。如果每个HTTP会话都启动新的TCP连接,那么在TCP三次握手中,至少要浪费1个RTT,这就是数百毫秒。
TCP慢启动则是为了解决网络拥堵问题。就像公路上必须有红绿灯一样,TCP连接之间会在不通过第三方仲裁的情况下,自行监控丢包与延迟的变化解决网络拥塞。其中一个重要手段,就是连接刚建立时先不要满载发送字节流(慢慢提升拥塞窗口的大小),这就是“慢启动”。可以想见,对于百G大带宽的服务器而言,一次只能发送10个MSS大小(即15KB,假定MSS为1500字节)的报文有多浪费。
因此,早在HTTP1.0时代,就有了KeepAlive长连接技术,到了HTTP/1.1更是直接写入RFC标准里。简而言之,就是传输完1个HTTP请求后,不要关闭TCP连接,继续将它复用在下一个HTTP请求中,下图是NGINX上配置KeepAlive的方法: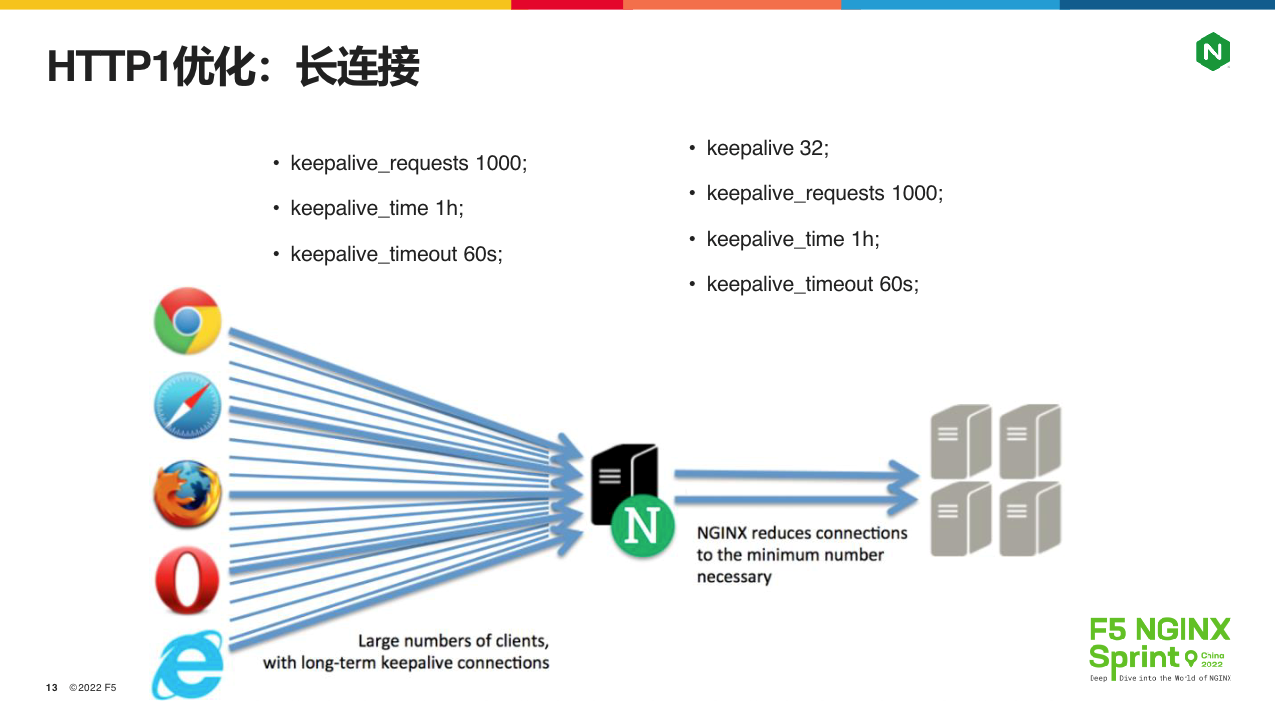
上图左边是客户端与NGINX间的长连接配置,右边是应用服务器与NGINX间的长连接配置,可以看到,它们并不完全相同。其中,相同的配置是keepalive_requests、keepalive_time和keepalive_timeout,分别放在server{}或者upstream{}配置块中,表示1个TCP连接最多可以承载 1000 个请求、保持 1 小时或者 60 秒的最大空闲时长,一旦不满足任一条件,连接就会关闭。比起RFC标准来,似乎复杂了不少,但这是做软件工程必备的思维方式,因为NGINX需要处理各种意外情况,有了这些限制,单一用户就不会占用太多资源。
而对于IDC内的上游服务器,NGINX必须在客户端关闭HTTP会话后,继续维护TCP连接池,这其实对于上游的应用服务器带来了一些压力,所以又多了一个 keepalive 配置,它可以限制连接池内的TCP连接数量。
HTTP2的增带宽
上文说了如何减少报文的往返次数,我们再来看如何增带宽。其实传输层与网络层也能做到,比如以太网MTU默认 1500 字节,但巨型帧技术早已成熟,服务器之间单个报文可以增加到 9000 字节。而且在 IPV6 协议中,IP报文更是超过了 65535 字节的限制。当然,今天的重点还是在应用层协议上。
2015年推出的HTTP2协议有很多新特性,但相对HTTP1最大的提升就是增加了单TCP连接的传输带宽,下图可以清晰的看到它带来的变化,从左边的14秒到右边的2秒,差不多有一个数量级的提升!
解释下上图的测试上下文:这张高清地球图片被拆成了大约 380 张图片,因此需要发起380个HTTP请求才能用JavaScript拼接成完整的图片。 我的验证环境是Chrome浏览器,因此左边的 HTTP 1.1 会同时并发 6 个 TCP 连接,每个连接依次传输60多张图片。右边的HTTP 2 则仅使用1个TCP连接,同时传输380个小图片(实际上是380个STREAM),这样带宽便可以充分使用,消除了HTTP语义简单性带来的响应等待问题。
HTTP 2还有很多优点,比如浏览器解析完HTML资源(例如 index.html )获得DOM 树后,会分析待下载的 CSS 、JavaScript或者多媒体资源,评价资源间的依赖程度和用户体验,从而对不同的STREAM设置优先级,这样可以在有限的总带宽下更有效的分配资源。再比如资源推送,当客户端下载了play.html后,服务器知道接下来浏览器一定需要jquery.js文件,于是就可以主动推送资源,如下图所示: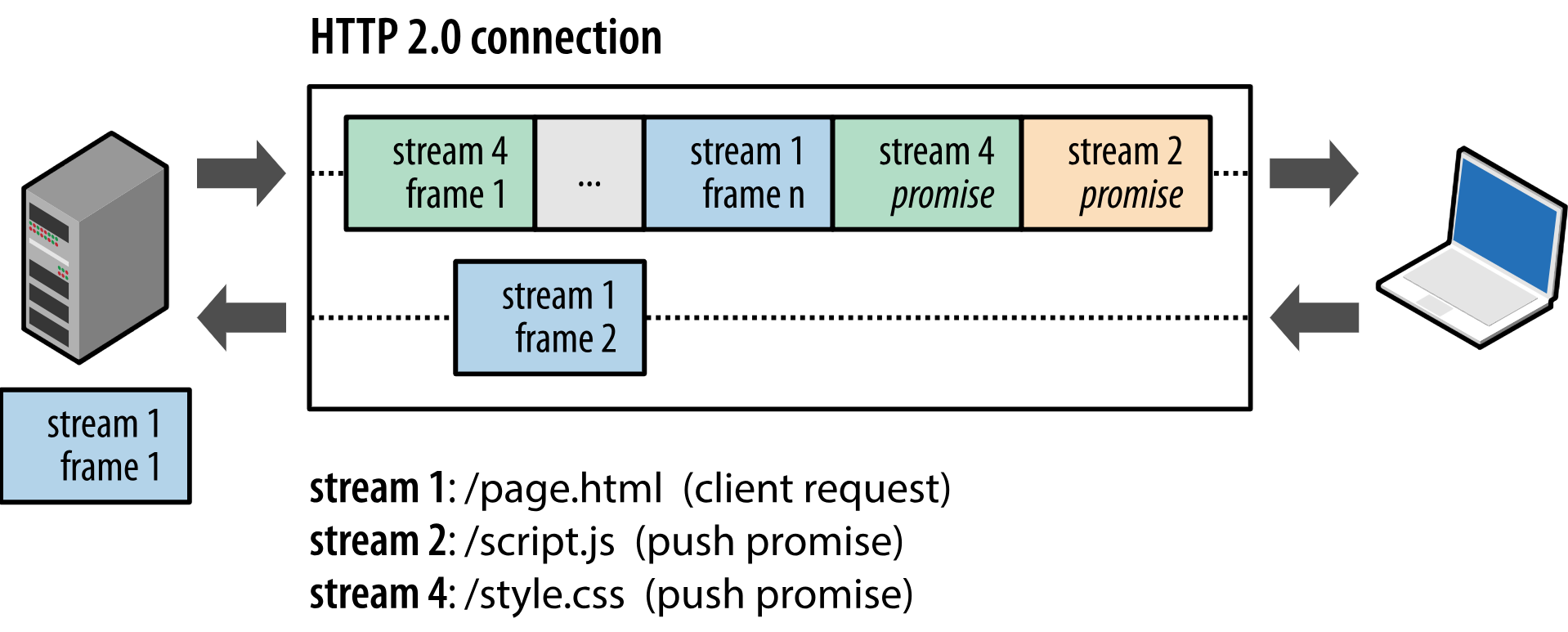
在NGINX上开启HTTP2非常简单,只要在listen指令最后添加http2参数即可。
当然HTTP 2协议并不是完美的,它的最大问题在于“队头阻塞”,如下图所示: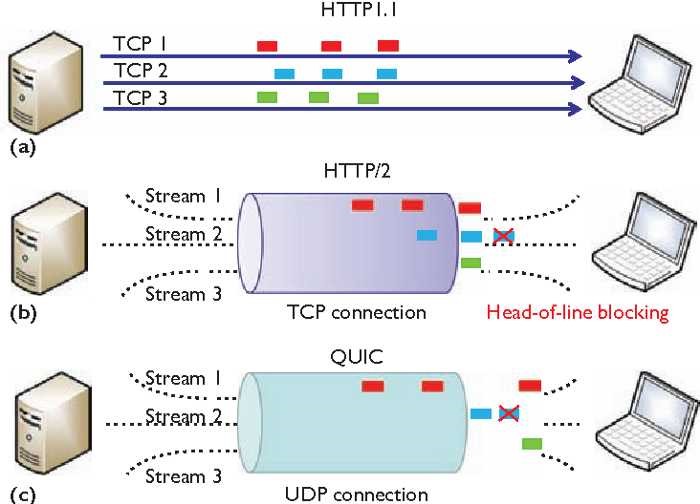
上图a场景的HTTP 1 协议中,蓝色报文的丢失并不会影响红色、绿色请求,但到了b场景的HTTP2协议,由于红、蓝、绿请求都承载在同1个 TCP 连接上,而TCP 又是一个有序字节流协议,所以蓝色报文的丢失不只影响了蓝色请求,还影响了红色、绿色请求,这就叫队头阻塞。HTTP3协议则通过UDP和quic层解决了这个问题,关于HTTP3我们后面再说。
TLS协议栈优化
接下来我们再来看 OSI表示层协议TLS/SSL的优化。在全栈加密的今天,绝大部分公网流量都是经由TLS协议加密的,而优化TLS除了在先进算法与兼容性、性能与安全性之间做权衡外,还要考虑系统架构约束的变化。
建立会话
先来看TLS会话握手,这是最消耗CPU性能的过程,通常单颗CPU核心的每秒新建数不过一千多,但更为关键的是,握手消耗的RTT时间更多,参见下图: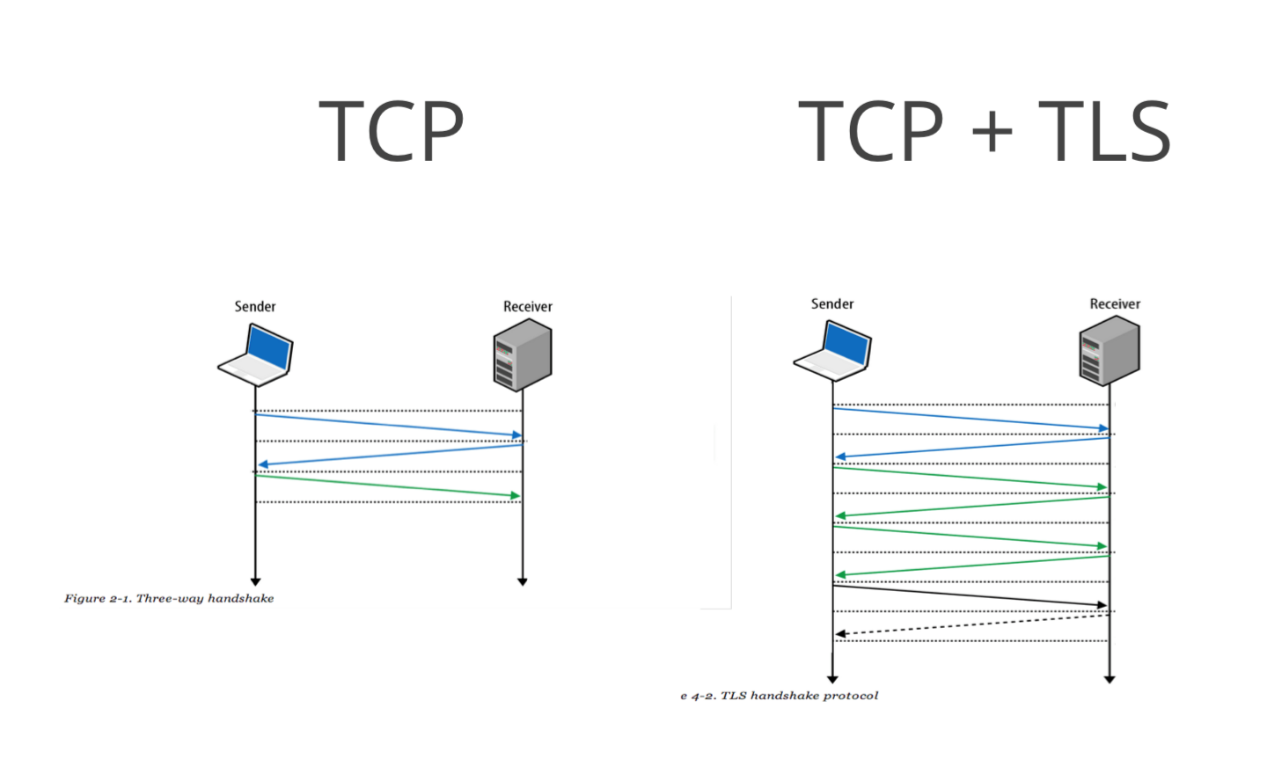
上图中右侧是以TLS1.2协议为例看会话建立过程的,相对于图左侧在TCP握手中消耗1个RTT(蓝色线条)之外,右侧共消耗了3个RTT(蓝色与绿色线条),这就接近1秒时延了。怎么解决呢?参见下图的TLS 1.3方案: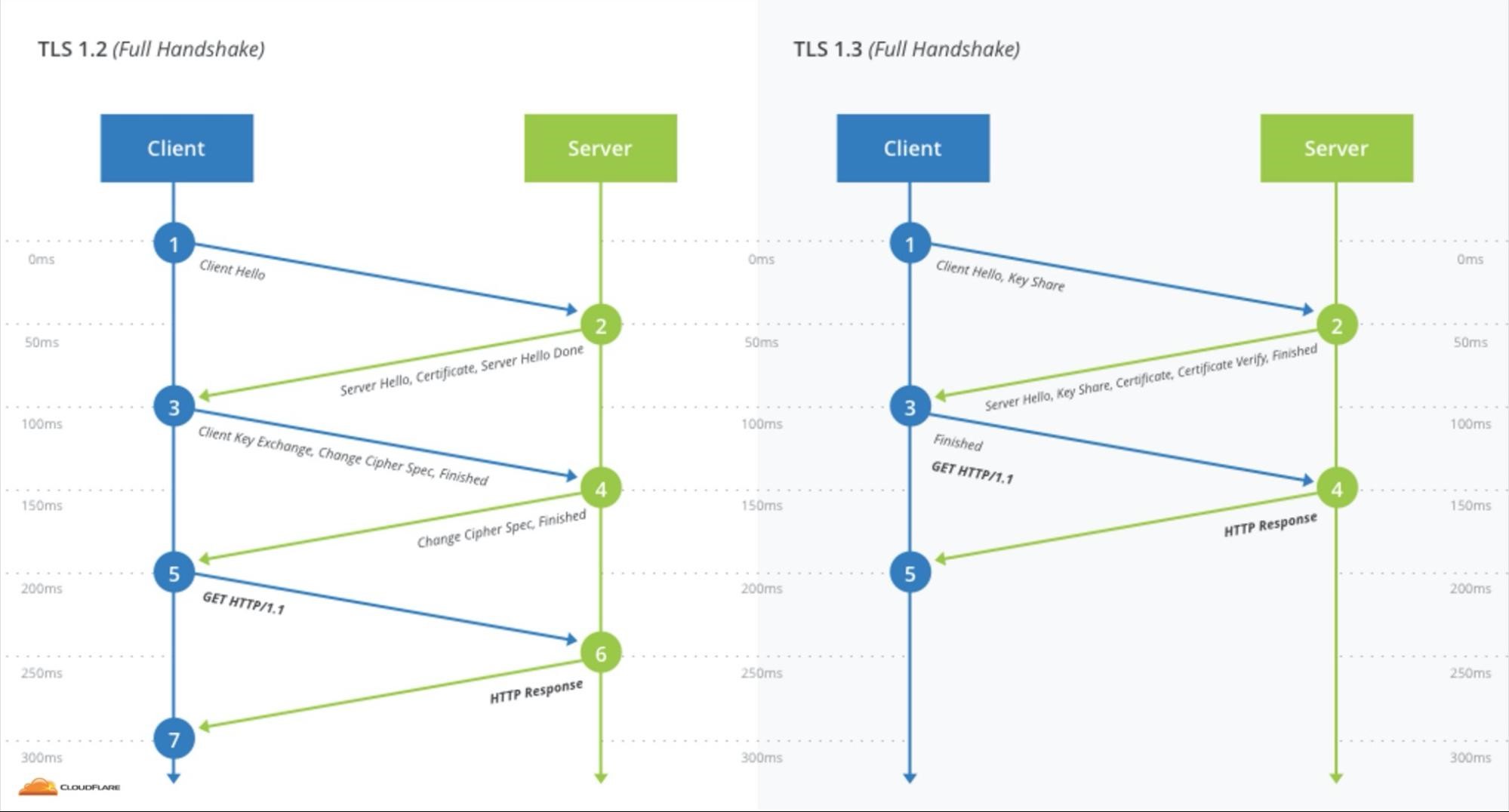
上图左侧,TLS1.2通过Client Hello、Server Hello、Client Key Exchange、Finished(或者可选的Server Key Exchange)4条消息在2个RTT中完成了握手。我们要分析下,为什么交换密钥不能从2次RTT降为1次RTT呢?这其实是能做到的,只要大幅减少加密算法(在TLS中被称为安全套件)的数量,就可以把Client Hello这个协商算法的消息与Client Key Exchange合并为一条消息,这就变成右图中的TLS 1. 3握手了。我们可以通过ssl_protocols指令配置NGINX支持的协议版本,但目前至少需要同时支持TLS 1.2和TLS 1.3,因为还有很多古老的客户端不兼容TLS1.3协议。
传输数据
再来看传输加密数据的过程,我们可以基于内核的kTLS提升性能。在介绍kTLS之前,咱们需要先回顾下HTTP缓存,这实际上是HTTP协议栈的优化内容,可又是NGINX使用kTLS的前置知识点,所以我放在这里简要介绍。
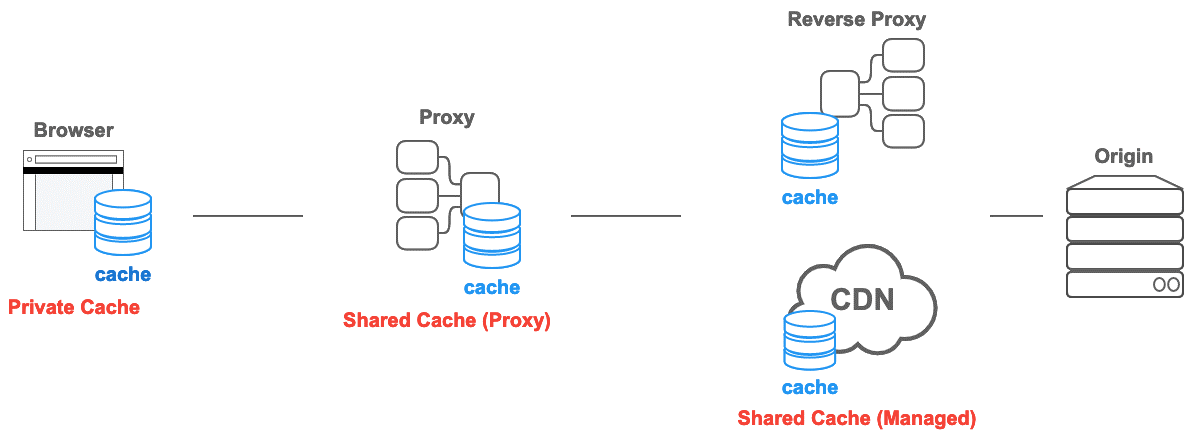
上图中,cache缓存可以存放在浏览器上,这时它的属性是private,只针对一个用户有效。缓存还可以存放在正向代理(参考科学上网)、反向代理(参考CDN)上,此时它的属性是public,可以被多个用户共享。缓存通过将内容放在空间上距离用户更近的位置上,降低用户下载内容的时间。
我们知道,NGINX可以使用Linux等操作系统提供的零拷贝技术(参见sendfile指令),将磁盘上的文件不通过worker进程就发送到网卡上。然而,openssl是运行在worker进程上的,一旦下游客户端走的是TLS流量,零拷贝就失效了,因为必须把磁盘上的文件读取到worker进程的内存空间上,才能使用openssl加密文件,然后再经由内核把加密后的字节流发送到网卡。所以,只要在内核中使用TLS协议加密流量,就可以继续使用零拷贝技术,如下图所示: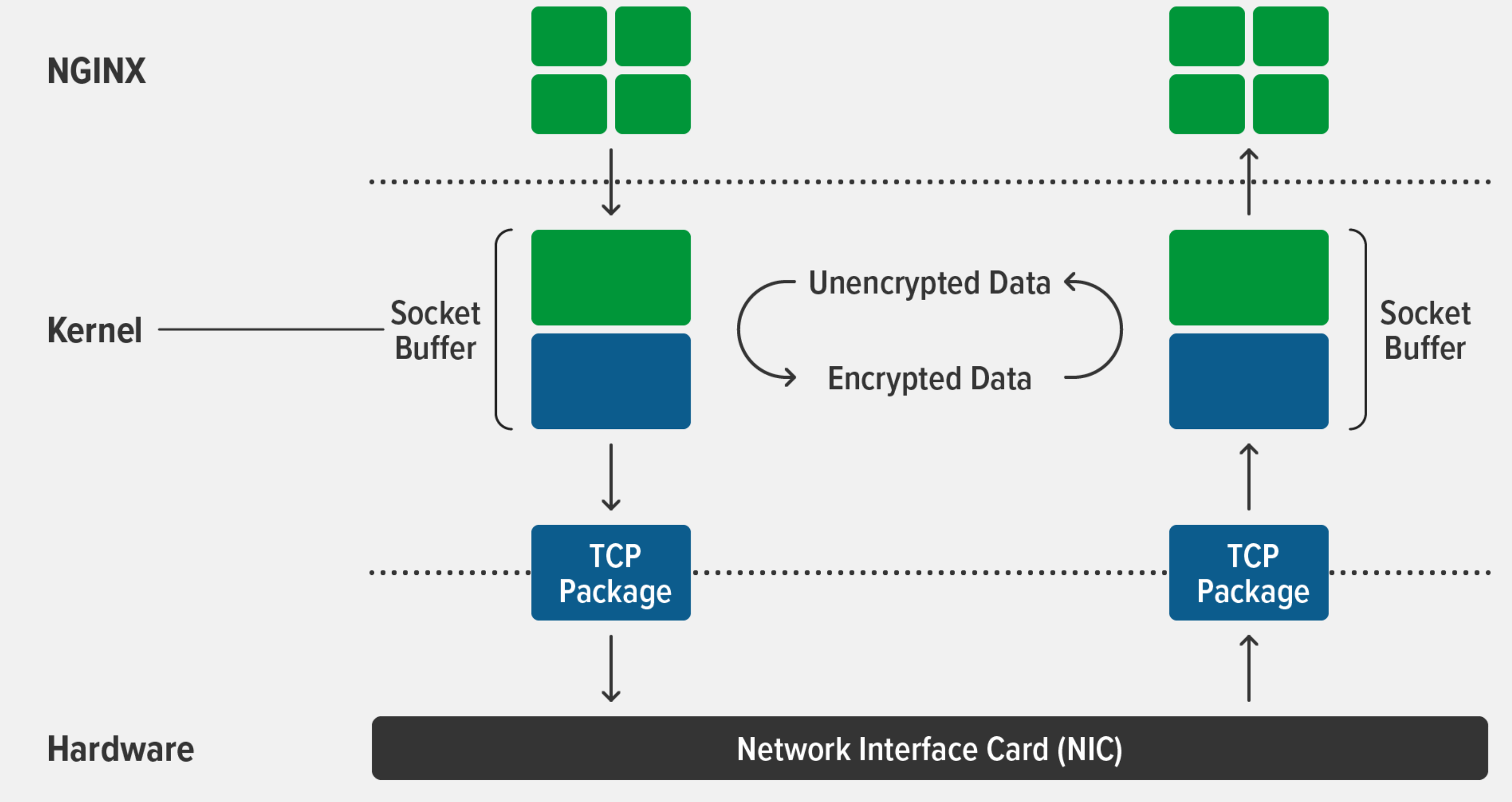
NGINX 1.21.4版本开始支持kTLS功能,通过ssl_conf_command Options KTLS;指令即可开启零拷贝TLS流量功能,具体参见这篇官方博客https://www.nginx.com/blog/improving-nginx-performance-with-kernel-tls/。
事实上如果不使用kTLS,在内核与worker进程间反复拷贝数据,造成的CPU消耗会越来越可观!关于这点,我们要从下图的内存发展趋势谈起: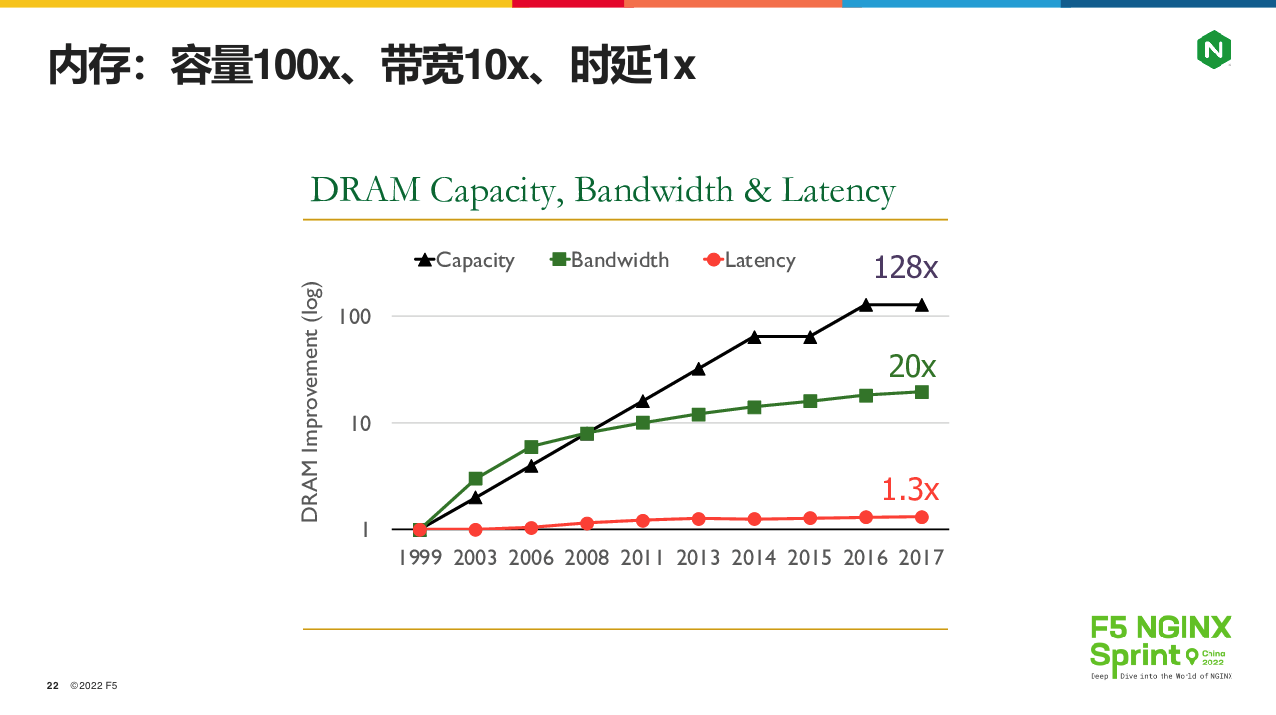
上图中,红色的线是内存访问时延,绿色的线是内存访问带宽,黑色的线是内存容量。可以看到,从1999年到2017年,内存容量翻了 100 多倍,而访问带宽只升了20 倍,内存访问时延则基本没有变化!这对开发人员提出了要求:缓存的作用越来越大,但是内存拷贝是次数必须降低。因此,当我们把加密过程通过kTLS放到内核中,压根不跟worker 进程接触后,就会有10% 到 20% 的性能提升(参考官网测试数据)。
TCP/IP协议栈优化
最后来看TCP / IP协议栈的优化。摩尔定律的失效,对TCP/IP协议栈的优化影响很大,如下图所示,CPU在向多核心方向发展: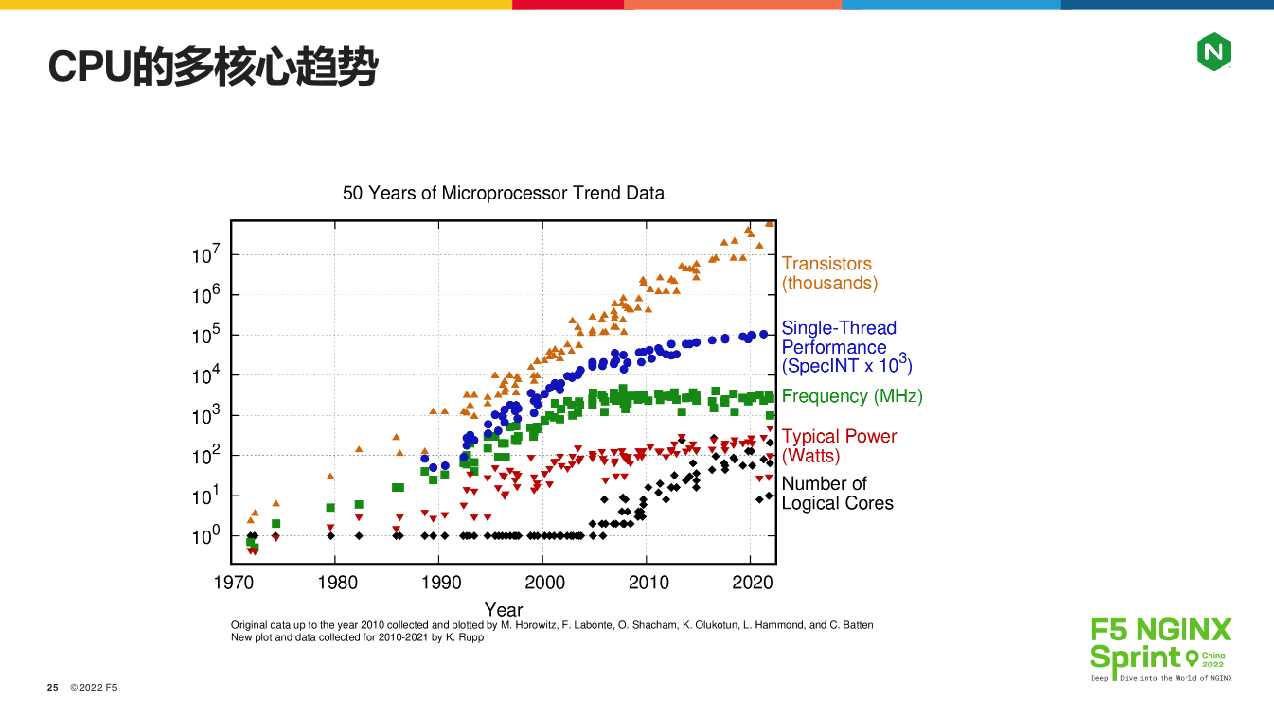
上图我们重点看绿、蓝、黑 3 条曲线。绿色曲线是 CPU 频率,从2004 年以后基本就不变了。蓝色曲线是CPU单核性能,略有提升是CPU架构优化和缓存带来的。黑色曲线则是CPU核心数,它的不断增加对开发人员的要求很高。具体到TCP/IP协议,就是操作系统的共享协议栈设计,带来的锁竞争概率直接上升!
现代OS都是分时操作系统,单核心CPU一样可以通过微观上的串行任务,实现宏观上的并发,而且这时的并行多任务在使用自旋锁时,几乎没有锁竞争问题。然而,一旦服务器使用了64核等CPU时,微观上就会有64个线程并行执行,对于高负载的NGINX来说锁冲突概率会非常高。此时你升级CPU,是不会带来线性性能提升的,与此同时,CPU的SI软中断百分比会急剧变大。
内核协议栈的设计,除了锁竞争问题外,还会引入3个问题。如下图所示,内核协议栈必须通过socket和系统调用与NGINX传递消息,因此系统调用导致的上下文切换、内核态与用户态间的内存拷贝、硬件NIC网卡与协议栈协同引入的软中断,都是不可忽视的因素: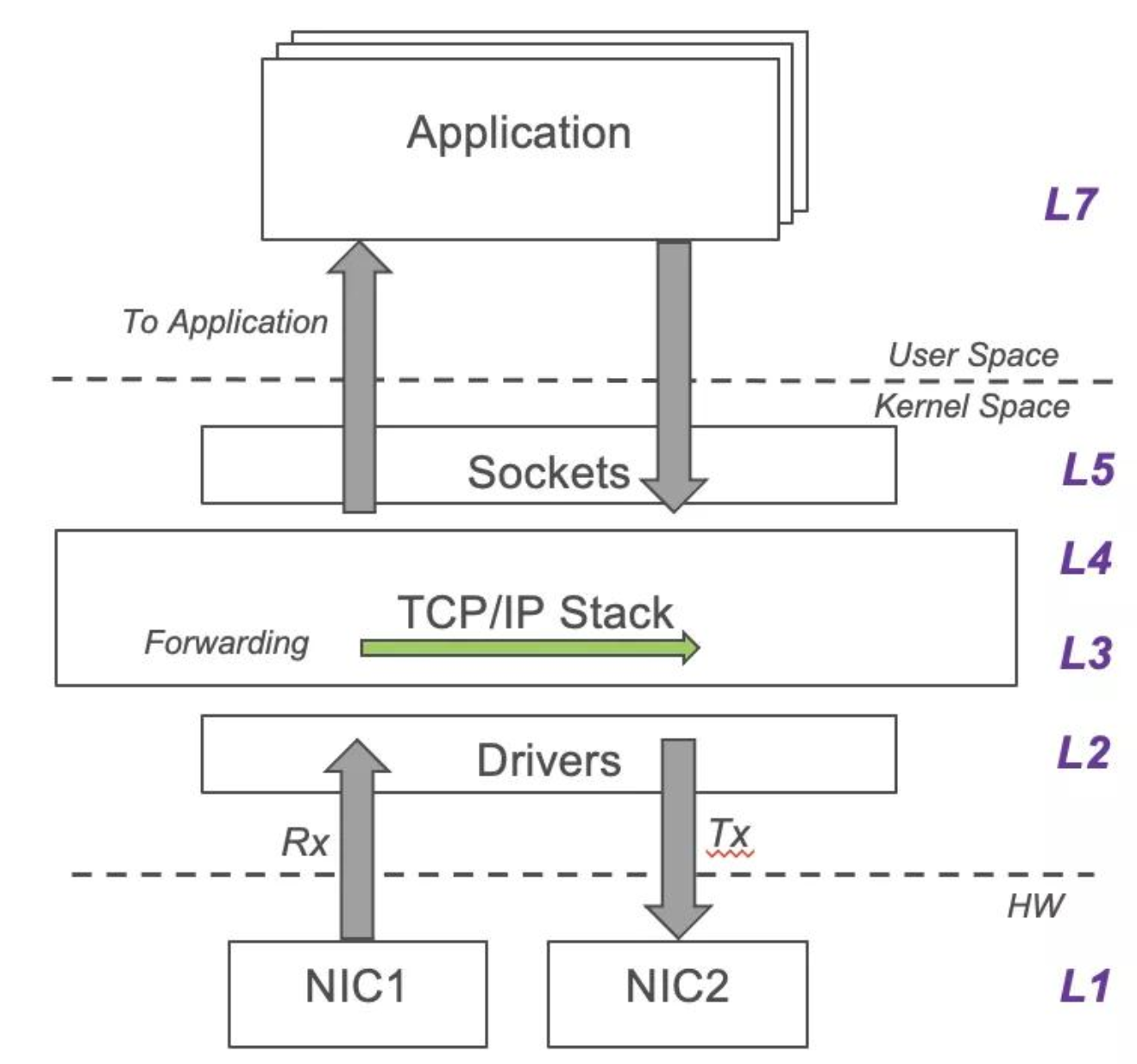
当然,上图的设计优点也很多,比如大幅减少了应用开发的难度,增强了操作系统的稳定性等。但当我们关注性能、优化协议栈时,就不得不使用诸如零拷贝、kTLS等特性,还要不断关注软中断进程ksoftirq的CPU占用率。这里简单解释下什么是软中断,如下图所示: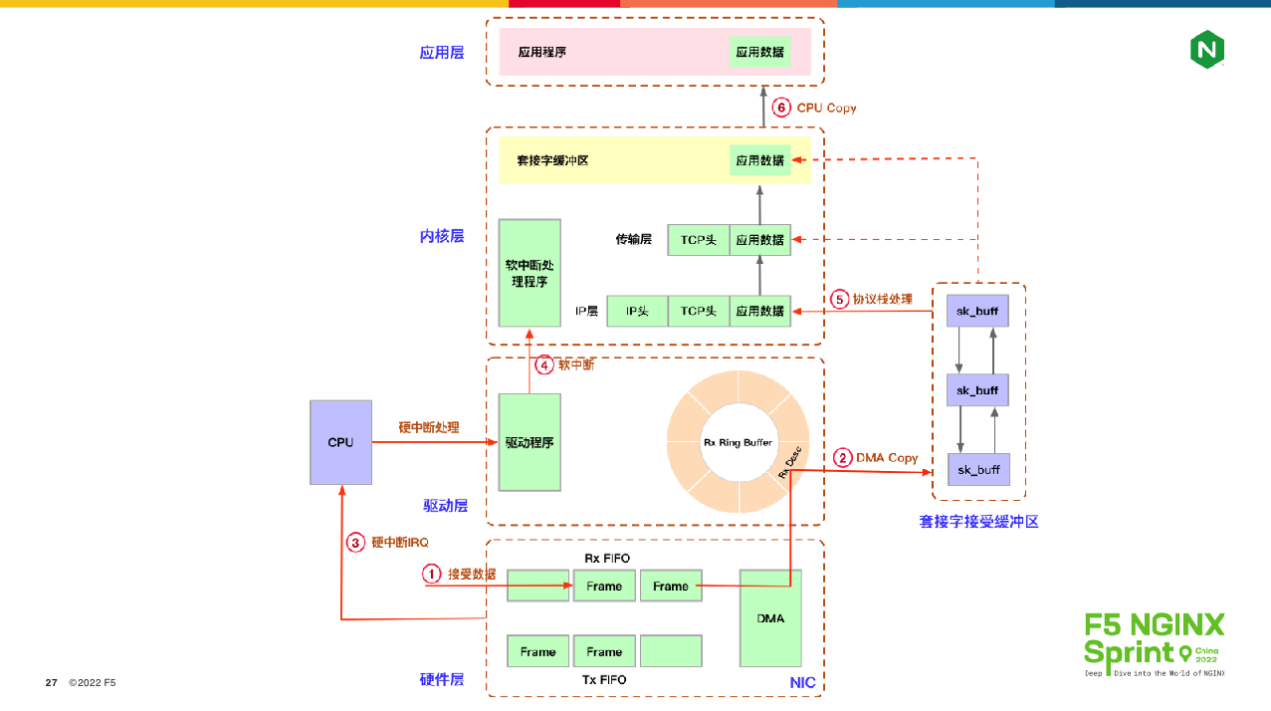
上图有6 个步骤,其中第1、2、3步是从网络中接收的报文复制到 sk_buffer 中,并发起硬中断通知操作系统;第4、5步则是操作系统收到软中断后,通过协议栈处理报文,此时 ksoftirq 进程是在工作的。把两个步骤分开是一种异步化设计,毕竟网卡是硬件,处理报文的速度必须足够快,而ksoftirq则可以有延迟。第6步就是NGINX通过epoll_wait 拿到就绪的socket,或者经由read 或者 write 等函数拷贝报文数据。可见,在这个过程中,软中断对我们的消耗是可观的。
那么,当服务器CPU核心增多时,如何解决上述问题呢?Intel dpdk加上用户态协议栈是一条可选的路径。如下图所示,dpdk允许用户态进程直接从网卡上读取接收到的报文,或者拷贝数据到网卡来发送报文,绕过内核协议栈: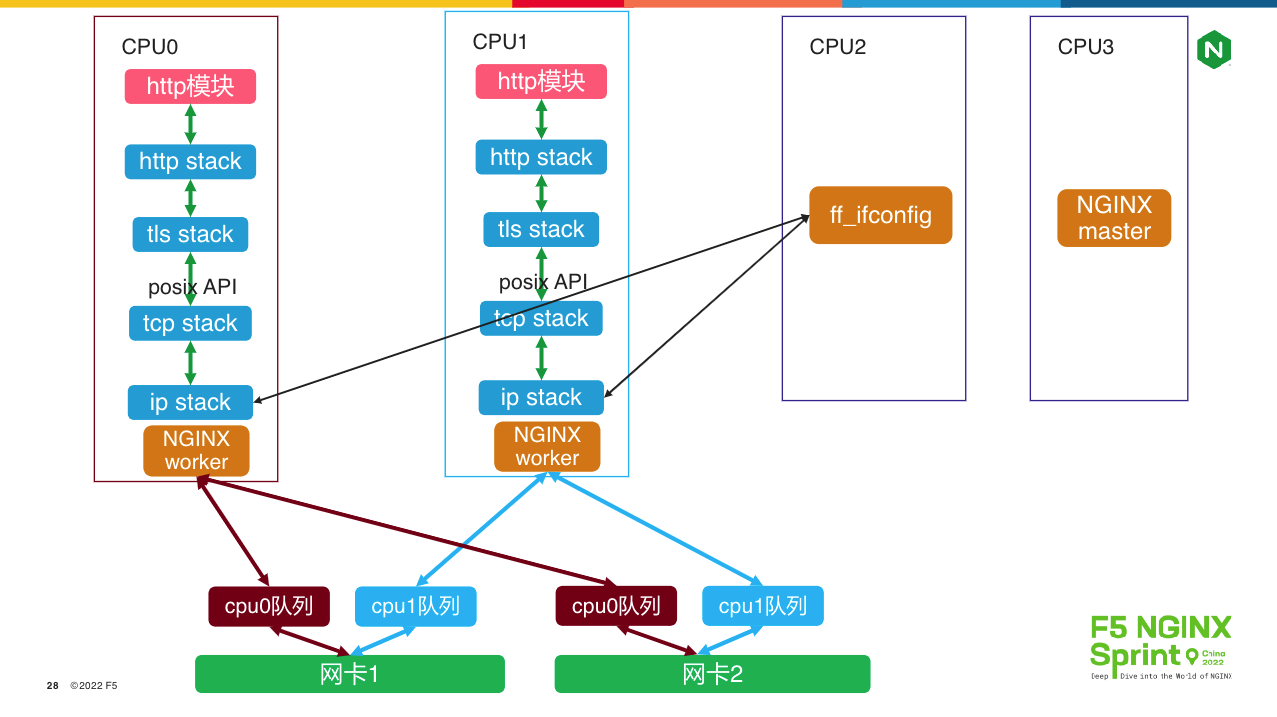
上图是腾讯f-stack给出的方案,它改造了freebsd操作系统的TCP/IP协议栈,对下通过dpdk与网卡交互,对上则以POSIX API的静态库形式,在 worker进程内为传输层之上提供服务。可以看到,由于每个NGINX worker进程内的IP、TCP协议栈都是独立的,所以当你修改IP地址时,不能使用操作系统的ifconfig或者nmcli命令,而是必须执行f-stack封装的ff_ifconfig命令,而且必须为每个worker进程分别执行脚本(使用-p指定进程ID),因此,管理每个worker进程的配置一致性是比较复杂的。
熟悉NGINX的同学都知道,所有worker子进程之间的地位是相同的。然而到了上图中的方案时,情况就不一样了。在多进程架构中,dpdk要求必须分清主次,也就是第1个fork出的worker子进程是主进程,它必须负责管理大页内存(huge page,dpdk必须使用这种管理模式,当然dpdk无锁内存池的设计非常高明!),而其他worker子进程则只是使用大页内存。这种设计导致NGINX reload模式会出问题,因为主worker退出、新建这段时间内,其他worker进程是不能提供服务的,这样NGINX的“热加载”功能就要大打折扣了。
worker进程的数量与网卡的数量并不一致,因此worker进程间必须通过哈希算法,各自处理网卡上收到的报文。由于每个worker进程绑定了一颗CPU核心,所以图中的cpu队列等价于worker进程处理报文的队列(dpdk是高性能网络框架,它只针对CPU设计独立的报文队列)。上图中,当蓝色报文到达网卡1时,会根据TCP四元组(在dpdk初始化时可通过f-stack.conf配置)分发到CPU1队列。worker0和worker1都会循环获取CPU队列中的报文,但worker0只取CPU0队列,所以worker1进程会获取到CPU1队列上的蓝色报文,经由进程内的独立TCP/IP协议栈(无须中断、无须加锁)处理完毕后,交由NGINX的epoll、各HTTP模块处理。可见,这种架构去除了软中断、系统调用、内核态用户态切换,大幅减少了内存拷贝次数,即使单worker性能也会有不少提升。但它的最大优势是多核心CPU,尤其是CPU核心达到32、64甚至更高时,无锁化设计带来的优势非常明显,可以轻松达到百万级CPS(每秒新建连接数)、上亿并发连接。
当然,这种带来高性能的独立协议栈设计,还引入了一个大麻烦:NGINX作为负载均衡使用时,一个会话上的客户端、上游服务器报文都必须在同一个worker进程内处理,这是普通的哈希算法无法做到的,如下图所示: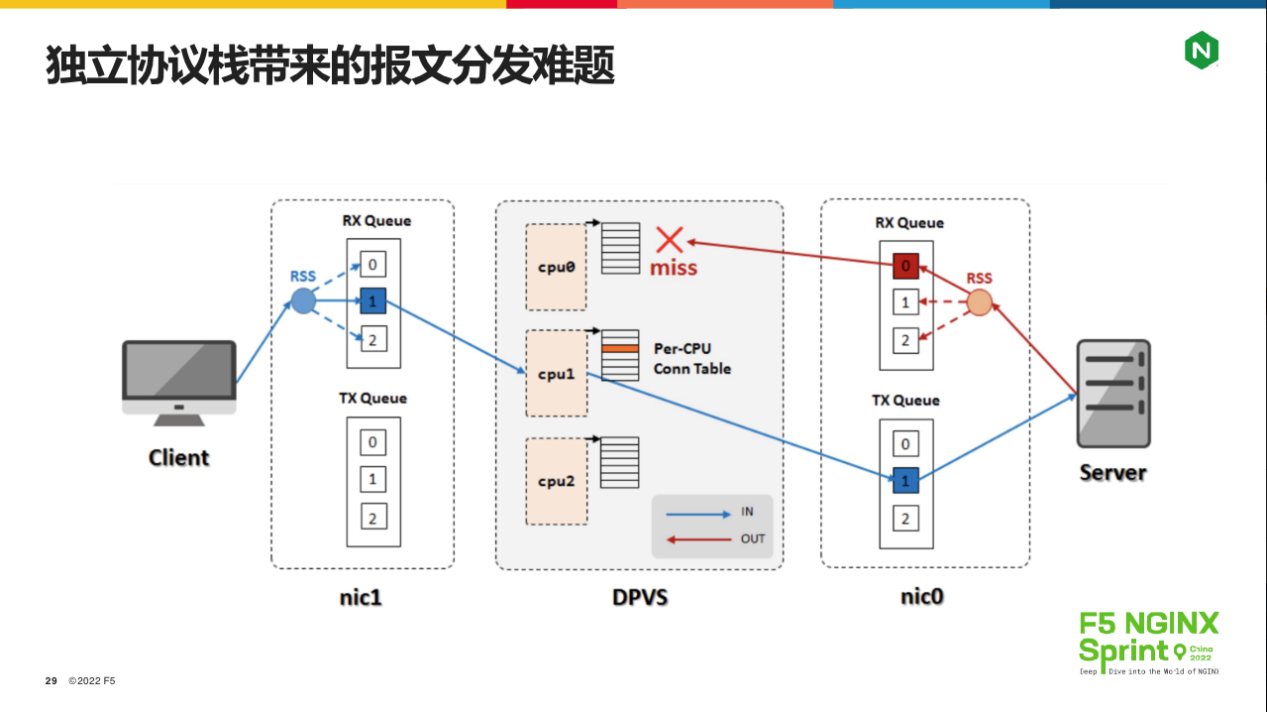
客户端发起的TCP连接由worker1进程处理,但worker1与上游服务器建立的连接,回包经由哈希算法,可能会落到worker0进程处理,这样数据就乱了!如何解决这个问题呢?f-stack和dpvs都给出了不太完美的方案。
f-stack在向上游发起TCP连接时,本地端口并不像从前一样找出一个空闲端口直接使用,而是从小到大反复测试(最大到65535),判断TCP四元组经由哈希函数的结果,如果本地端口导致哈希值没有落在当前worker进程上,就换一个,直到符合为止(O(n)时间复杂度!)。这套解决方案优点是与硬件无关,缺点则是性能非常差!
Dpvs的解决方案则必须使用支持fdir(Intel® Ethernet Flow Director)的网卡。Fdir技术允许程序基于TCP目的端口(其他四元组元素当然也可以)设置CPU队列的分发规则,比如,worker0进程发起的TCP连接本地端口只从1-10000(实际当然不是基于整数区间,而是按二进制bit位规划的),而worker1进程的本地端口则只从10001到20000,这样两个进程发送SYN报文时,就可以确保来自上游的SYN+ACK报文可以回到原worker进程了。这套方案的优点是性能很好,缺点则是绑定了硬件和应用代码(预留端口),而且dpdk的版本还必须与网卡配套才能正常工作。
事实上HTTP 3协议也面临类似的问题,只是它的表现形式在于“连接复用”功能!为了解决移动设备频繁更换IP地址导致的TCP断网重连问题,HTTP 3不再基于TCP四元组定义连接,而是设计了1个64位的connection ID,只要该ID不变,客户端在一段时间内(例如1分钟)断网重连后,依然可以复用原先的连接。然而,目前的操作系统内核只会基于TCP目的端口分发进程,并不知道每个worker进程上具体处理的connection ID,这也是NGINX迟迟无法推出HTTP3版本的原因(解决方案是高度耦合的eBPF模块,因此QUIC分支目前仍没有合并到主干)。
最后总结一下。今天我介绍了HTTP协议栈、TLS/SSL 协议栈和 TCP/IP 协议栈的优化思路,最终如何应用还要根据实际的应用场景来拍板,但取舍前一定要先了解当前协议栈的性能天花板在哪。好,谢谢大家,祝大家今天下午后面的旅程一切顺利!